
Tác giả: Melody Dye, Chaitanya Ekanadham, Avneesh Saluja, Ashish Rastogi
Thuỳ biên dịch từ Tech Blog của Netflix
Chiến lược phát triển hiện tại của Netflix, theo như họ tuyên bố, là tập trung vào phát triển nội dung ở quy mô cực kỳ lớn, nhằm phục vụ cho hơn 195 triệu thành viên (và tiếp tục tăng) tại hơn 190 quốc gia trên thế giới với thị hiếu hết sức đa dạng và phong phú. Các giám đốc mảng sản xuất nội dung, marketing và studio có nhiệm vụ phải đưa ra các quyết định quan trọng nhằm tối đa hóa tiềm năng của mỗi phim hoặc series, khiến khán giả hứng thú từ giai đoạn quảng cáo cho tới khi phim phát. Và để hỗ trợ việc đưa ra các quyết định đó, Netflix viện đến sự giúp đỡ của đội ngũ kỹ sư hàng đầu trong ngành và các công cụ machine learning của họ.
Việc quyết định đặt hàng sản xuất một phim hoặc series nào đó (từ đây gọi tắt là phim) là một quyết định sáng tạo. Các giám đốc cần xem xét nhiều yếu tố bao gồm chất lượng kể chuyện, mối quan hệ với bối cảnh xã hội hoặc hệ tư tưởng hiện tại, các quan hệ tài năng sáng tạo, cũng như thành phần và quy mô khán giả, cùng nhiều yếu tố có liên quan khác. Chi phí sản xuất thì đắt đỏ, mà kết quả kinh doanh thì lại khó dự đoán. Vậy nên, để giảm thiểu sự bấp bênh, không chắc chắn này, các giám đốc điều hành trong toàn bộ ngành công nghiệp giải trí luôn phải tham khảo dữ liệu lịch sử để giúp mô tả đặc điểm của khán giả tiềm năng của phim, nếu có. Hai câu hỏi chính cần phải giải quyết là:
- Có thể so sánh được với những phim nào và so sánh như thế nào?
- Quy mô khán giả mong đợi là bao nhiêu và ở những khu vực nào?
Quy mô khán giả ngày càng lớn hơn và đa dạng hơn khiến cho việc trả lời các câu hỏi này càng trở nên khó khăn hơn nếu sử dụng các phương pháp thông thường, vốn dựa trên một số ít phim đi trước và chỉ số hiệu suất tương đương riêng của chúng (ví dụ như doanh thu phòng vé, xếp hạng Neilsen…) Do đó, các kỹ sư ở Netflix đã sáng tạo phương pháp phân tích mới sử dụng machine learning và mô hình thống kê để hỗ trợ những người ra quyết định sáng tạo trong việc giải quyết các câu hỏi trên ở quy mô toàn cầu. Ưu điểm chính của kỹ thuật này gồm hai phần. Thứ nhất, nó thu thập được dữ liệu từ nhiều phim đã sản xuất hơn (trên toàn thế giới cũng như tại một khu vực cụ thể). Thứ hai, chúng tận dụng các dữ liệu này một cách hiệu quả hơn bằng cách cô lập các thành phần (ví dụ như các yếu tố chủ đề) có liên quan đến phim được đề cập.
Phương pháp tiếp cận này bắt đầu từ transfer learning (các mô hình truyền đạt cho nhau khả năng mà mỗi mô hình có thể làm được), theo đó hiệu suất của mỗi tác vụ đích được cải thiện bằng cách tận dụng các tham số mô hình đã học trên một tác vụ nguồn riêng biệt nhưng có liên quan. Netflix xác định một tập hợp các tác vụ nguồn ít nhiều có liên quan đến các tác vụ đích dựa trên hai câu hỏi ở trên. Đối với mỗi tác vụ nguồn, họ tìm hiểu một mô hình dựa trên một tập hợp lớn nhiều phim đã được sản xuất, tận dụng các thông tin như metadata của phim (ví dụ: thể loại, thời lượng, nó là series hay là phim điện ảnh) cũng như các thẻ (tag) hoặc mô tả do các domain expert tuyển lựa giới thiệu chủ đề/cốt truyện của phim. Một khi đã nắm được mô hình này, các thông số mô hình được trích xuất thành biểu diễn số (numerical representation) hoặc embedding (chuyển dữ liệu chữ viết thô thành dữ liệu số thực, sau đó đưa dữ liệu số thực này vào các mô hình học) của phim. Các embedding này sau đó được dùng như đầu vào cho các mô hình hạ nguồn chuyên cho các tác vụ đích để xử lý một tập hợp phim nhỏ hơn có liên quan chặt chẽ, trực tiếp đến các quyết định nội dung (hình 1). Tất cả các mô hình đều được phát triển và triển khai bằng cách sử dụng metaflow, khung mã nguồn mở của Netflix để đưa các mô hình vào sản xuất.
Để đánh giá mức độ hữu dụng của các embedding này, các kỹ sư của Netflix nhìn vào hai chỉ báo: 1) Chúng có cải thiện hiệu suất trên tác vụ đích thông qua các mô hình hạ nguồn không? Và cũng quan trọng không kém, 2) Chúng có hữu ích cho các đối tác sáng tạo hay không, tức là chúng có cung cấp một hiểu biết thấu đáo hoặc tạo điều kiện để so sánh một cách phù hợp, đúng đắn (ví dụ: tiết lộ rằng hai phim cùng thu hút một phân khúc khán giả giống nhau, hay khán giả từ hai quốc gia đó có hành vi xem tương tự nhau)? Những cân nhắc này là chìa khóa trong việc cung cấp thông tin cho việc mở ra các hướng nghiên cứu và đổi mới tiếp theo.
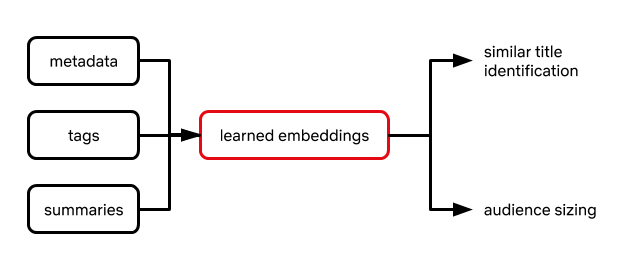
Các phim tương đương
Trong ngành công nghiệp giải trí, người ta thường đặt một dự án mới vào bối cảnh của các phim đã sản xuất trước đó. Ví dụ, một giám đốc sáng tạo trong quá trình phát triển một bộ phim sẽ tự hỏi: Bộ phim teen này mang đến các rung cảm trong sáng, lãng mạn như của “To All the Boys I’ve Loved Before” hay nó theo kiểu hài đen (dark comedy) như kiểu “The End of the F***ing World”? Tương tự, một giám đốc marketing khi điều chỉnh câu elevator pitch (lời quảng cáo trong thang máy – phát biểu ngắn gọn phác thảo một ý tưởng cho một sản phẩm, dịch vụ hoặc dự án) của mình sẽ tóm tắt bộ phim bằng câu: “Nỗi lo lắng hiện sinh của Eternal Sunshine of the Spotless Mind gặp chủ nghĩa siêu thực rực rỡ của The One I Love.”
Để làm cho các so sánh này phong phú hơn nữa, các phim này được “nhúng” trong một không gian đa chiều hay “bản đồ tương đồng”, trong đó nhiều phim tương tự nhau xuất hiện gần nhau hơn đối với một một đơn vị đo khoảng cách không gian chẳng hạn như khoảng cách Euclide. Sau đó “bản đồ tương đồng” được sử dụng để xác định các cụm phim có các yếu tố chung (hình 2), cũng như chỉ ra các phim ứng viên tương đương cho một phim chưa phát hành.
Đáng chú ý, không có một “chân lý” vững chắc nào về việc cái gì là tương đương: các embedding được tối ưu hoá trên nhiều tác vụ nguồn khác nhau sẽ mang lại các bản đồ tương đồng khác nhau. Ví dụ, nếu lấy các embedding từ một mô hình được phân loại dựa trên thể loại, bản đồ kết quả sẽ thu hẹp khoảng cách giữa các phim có chủ đề giống nhau (hình 2). Ngược lại, các embedding bắt nguồn từ một mô hình dự đoán quy mô khán giả sẽ điều chỉnh các phim có đặc điểm hiệu suất tương đương nhau. Bằng cách cung cấp nhiều điểm nhìn khác nhau về cách một bộ phim nhất định nằm tương quan trong một vũ trụ nội dung rộng lớn hơn, các bản đồ tương đồng này cung cấp cho những người ra quyết định sáng tạo một công cụ quý báu để hình thành tư tưởng và khám phá.

Transfer learning cho các tác vụ dự đoán quy mô khán giả
Một đầu vào quan trọng khác cho những người ra quyết định nội dung là ước tính quy mô khán giả tiềm năng lớn nhỏ ra sao (và nếu được, lượng khán giả này phân bổ ra sao trên các khu vực địa lý). Ví dụ, biết rằng phim này có thể thu hút khán giả chủ yếu ở Tây Ban Nha, cùng với một lượng lớn khán giả ở Mexico, Brazil, và Argentina sẽ giúp bạn quyết định được cách thức quảng bá phim hiệu quả nhất, và những nội dung địa phương hóa (như phụ đề, lồng tiếng) cần chuẩn bị trước.
Dự đoán quy mô khán giả tiềm năng của một phim là một vấn đề phức tạp theo đúng nghĩa đen của nó. Chúng ta sẽ nói chi tiết về phương pháp xử lý vấn đề này sau. Trong bài viết này, chúng ta sẽ chỉ nói một chút về cách các embedding được tận dụng để giúp giải quyết vấn đề này. Có thể thêm bất kỳ kết hợp nào sau đây dưới dạng các tính năng trong một khung mô hình được giám sát để dự đoán quy mô khán giả ở một quốc gia nhất định:
- Embedding của một phim
- Embedding của một quốc gia muốn dự đoán quy mô khán giả
- Quy mô khán giả của các phim đã sản xuất với các embedding tương tự (hoặc một tập hợp của chúng)
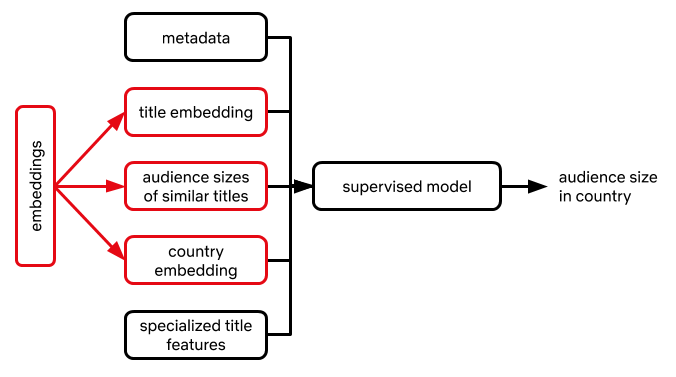
Ví dụ, nếu muốn dự đoán quy mô khán giả của một phim hài đen ở Brazil, Netflix tận dụng các bản đồ tương đồng đã nói ở trên để xác định các phim hài đen tương tự với quy mô khán giả quan sát được ở Brazil. Sau đó thêm các quy mô khán giả quan sát được này (hoặc một số trung bình cộng dựa trên sự tương đồng) làm đặc điểm. Các đặc điểm này có thể diễn giải được (chúng được liên kết với các phim đã biết và người ta có thể lập luận/tranh luận về việc liệu hiệu suất của các phim này có nên là một yếu tố ảnh hưởng đến dự đoán hay không) và cải thiện đáng kể độ chính xác của dự đoán.
Học các embedding
Làm thế nào để tạo ra các embedding này? Bước đầu tiên là xác định các tác vụ nguồn sẽ tạo các embedding hữu dụng cho việc tiêu thụ mô hình hạ nguồn. Ở đây chúng ta sẽ nói về hai loại tác vụ: được giám sát và tự giám sát.
Động lực chính của transfer learning là “đào tạo trước” các tham số của mô hình bằng cách học chúng trước từ một tác vụ nguồn có liên quan mà Netflix có nhiều dữ liệu đào tạo hơn. Kiểm tra dữ liệu mà mình có trong tay, Netflix thấy rằng bất kỳ phim nào mà họ có với đủ dữ liệu xem, họ có thể (1) phân loại phim dựa trên những người đã xem nó (hay còn gọi là “danh mục nội dung”) và (2) quan sát số lượng người xem ở mỗi quốc gia (quy mô khán giả). Từ thông tin cấp-phim này, họ đặt ra các tác vụ giám sát quá trình học:
- {metadata, tags, tóm tắt} → danh mục nội dung
- {metadata, tags, tóm tắt, quốc gia} → quy mô khán giả tại quốc gia đó
Khi triển khai các giải pháp cụ thể cho các tác vụ này, hai quyết định mô hình hoá quan trọng cần phải đưa ra là a) một phương pháp phù hợp (“bộ mã hoá” – encoder) để chuyển đổi các đặc tính cấp-phim (metadata, tag, tóm tắt) thành một đại diện phù hợp cho mô hình dự đoán và b) một mô hình (“bộ dự đoán” – predictor) để dự đoán các nhãn (danh mục nội dung, quy mô khán giả) được gán cho một phim đã mã hoá. Vì mục tiêu là tìm hiểu cách một vài embedding đa dụng có thể dùng trong nhiều trường hợp khác nhau, họ thường thích các mẫu nhiều tham số hơn cho bộ mã hoá và các mẫu đơn giản hơn cho bộ dự đoán.
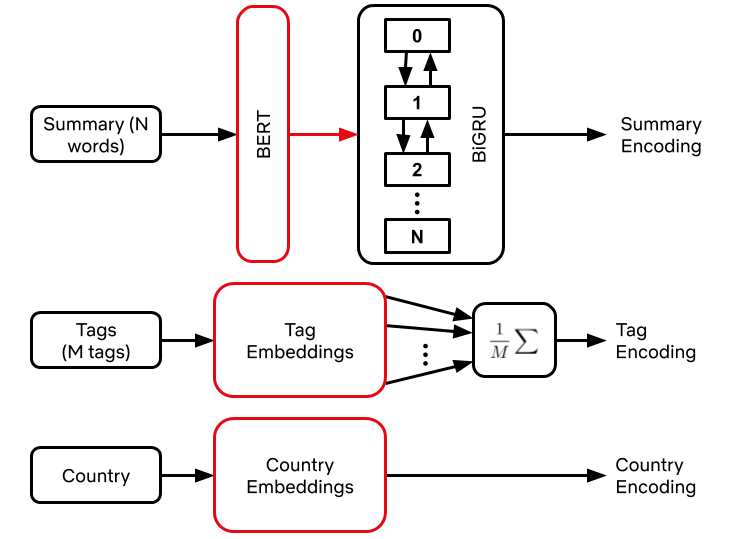
Lựa chọn bộ mã hóa (hình 4) phụ thuộc vào loại đầu vào. Đối với một tóm tắt bằng văn bản, Netflix tận dụng các mô hình được đào tạo trước như BERT để cung cấp các embedding phụ thuộc ngữ cảnh từ, sau đó được chạy qua một kiến trúc kiểu mạng thần kinh quy hồi, như một LSTM hoặc GRU hai chiều. Đối với các tag, họ học trực tiếp các biểu diễn thẻ bằng cách xem xét mỗi phim như một bộ sự tập tag, hoặc “túi-tag”. Đối với các mô hình quy mô khán gián mà trong đó các dự đoán dựa trên một quốc gia cụ thể, họ cũng học trực tiếp từ các embedding của nước đó và nối embedding kết quả với biểu diễn dựa trên thẻ hoặc tóm tắt. Về cơ bản, việc chuyển đổi mỗi thẻ và quốc gia thành embedding kết quả được thực hiện qua bảng tra cứu (lookup table).
Tương tự như vậy, bộ dự đoán phụ thuộc vào tác vụ. Đối với các dự đoán danh mục, Netflix đào tạo một mô hình tuyến tính phía trên của biểu diễn bộ mã hóa, áp dụng một phép toán softmax (hàm trung bình mũ) và giảm hàm mất mát (negative log likelihood). Đối với việc dự đoán quy mô khán giả, họ sử dụng một mạng thần kinh truyền thẳng (feedforward neural network) tầng ẩn (hidden-layer) đơn để tối thiểu hoá sai số toàn phương trung bình (mean squared error) cho một cặp phim-quốc gia xác định. Cả bộ mã hoá và bộ dự đoán đều được tối ưu hoá thông qua truyền ngược (backpropagation – viết tắt của “backward propagation of errors” tức là “truyền ngược của sai số”), và biểu diễn được bộ mã hoá tối ưu tạo ra được sử dụng trong các mô hình hạ nguồn.
Tự giám sát
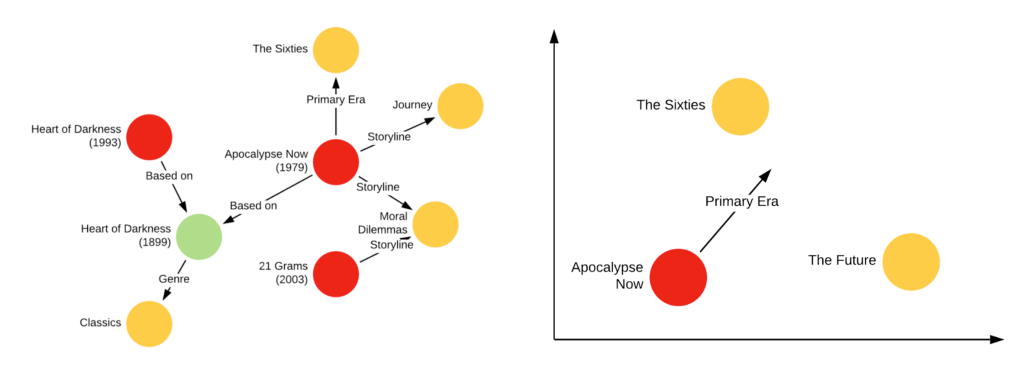
Sơ đồ trí thức là cấu trúc dữ liệu dựa trên đồ thị trừu tượng mà các quan hệ mã hoá (các cạnh) giữa các thực thể (node). Mỗi cạnh trong đồ thị, tức là bộ ba quan hệ đầu đuôi, được biết đến như một dữ kiện, và theo cách này, một tập hợp các dữ kiện (tức là “kiến thức”) dẫn đến một đồ thị. Mặc dù vậy, sức mạnh thực sự của biểu đồ là thông tin được chứa trong cấu trúc quan hệ.
Tại Netflix, người ta áp dụng khái niệm này cho các kiến thức có trong vũ trụ nội dung. Xem xét một biểu đồ tinh giản có các node bao gồm 3 loại thực thể: {phim, sổ, metagata tag) và có các quan hệ mã hoá giữa chúng (ví dụ: “Apocalypse Now dựa trên Heart of Darkness”; “21 Grams có cốt truyện xoay quanh những tình huống khó xử về đạo đức”) như được minh hoạ trong hình 5. Các dữ kiện có thể được hiểu dưới dạng bộ ba (h,r,t), ví dụ (Apocalypse Now, dựa_trên, Heart of Darkness), (21 Grams, cốt truyện, những tình huống khó xử về đạo đức). Tiếp theo, chúng ta có thể tạo ra một tác vụ học tự giám sát trong đó chúng ta chọn ngẫu nhiên các cạnh trong biểu đồ để tạo thành một tập kiểm tra, và điều kiện trên toàn bộ phần còn lại của biểu đồ để dự đoạn các cạnh thiếu. Tác vụ này, còn được gọi là dự đoán liên kết, cho phép chúng tô học các embedding cho tất cả các thực thể trong biểu đồ. Có nhiều cách tiếp cận để phân tách các embedding và cách tiếp cận hiện tại của Netflix dựa trên thuật toán TransE. TransE học một embedding F để giảm thiểu khoảng cách Euclide trung bình giữa (F(h) + F(r)) and F(t).
Việc tự giám sát rất quan trọng vì nó cho phép đào tạo trên các phim ở cả trong và ngoài dịch vụ của Netflix, mở rộng đáng kể bộ đào tạo và mở khoá nhiều lợi ích hơn từ transfer learning. Các embedding kết quả sau đó có thể được dùng trong các mô hình tương tự đã nói ở trên và các mô hình dự đoán quy mô khán giả.
Kết
Việc sản xuất nội dung là rất khó khăn. Nó liên quan đến nhiều yếu tố khác nhau và đòi hỏi sự đầu tư đáng kể, tất cả cho một kết quả rất khó dự đoán. Vậy nên, việc ứng dụng các công cụ AI trong việc xác định các phim có liên quan và dự đoán quy mô khán giả giúp Netflix đưa ra những quyết định hợp lý hơn nhằm tăng xác suất thành công của mình, nhất là trong bối cảnh cả số người đăng ký lẫn danh mục phim của Netflix ngày càng trở nên phát triển và đa dạng hơn.



Bình luận về bài viết này